Field¶
The Field object is essentially a 5-dimensional array (spacetime plus 1 internal axis). It provides the following specialized structure useful for simulation (not exhaustive):
Common communication patterns between distributed compute nodes
Iterators to simplify common loop ranges
Flexible storage: storage pattern and index space are independent
OpenMP aware: design accounts for multithreading and vectorization
Finite volumes: awareness of structured grid metrics
Slice operations
Index Space¶
No matter what the storage pattern is, the order of array indices always has the same meaning: 1 time, followed by 3 space, followed by 1 internal. The meaning of the spatial indices depends on the coordinate system chosen. The ordering for the various coordinate systems is as follows.
The range of the component index is ![[0,1,...,N-1]](_images/math/2e3749d32ec3fa8d7dc0952914774bc75a1b5a78.png) , where N is the number of components. The range of a coordinate index is
, where N is the number of components. The range of a coordinate index is ![[1-L,2-L,...,M+L]](_images/math/077b18a2f896c8c13c22e43e21055b9c69e2bc26.png) , where M is the number of coordinate points along the axis in question, and L is the number of ghost cell layers.
, where M is the number of coordinate points along the axis in question, and L is the number of ghost cell layers.
Note
The coordinate index can be negative if there are two or more ghost cell layers.
Tip
The interior cell indices always range from 1 through M, no matter the ghost cell layers.
Loopless Operations¶
For operations acting uniformly on a field, there is no need for an explicit loop. For example, to set all the components in a field to unity:
some_field = 1.0;
Most C++ operators are supported. For example, to divide the whole field by 3:
some_field /= 3.0;
Index Based Loops¶
You can loop through a field in legacy fashion:
int n = 1; // time index, often just 1
int c = 0; // internal index, starts at 0, sometimes just 1
for (int i=0;i<5;i++)
for (int j=0;j<5;j++)
for (int k=0;k<5;k++)
some_field(n,i,j,k,c) = 1.0;
This sets the first component to unity for the range of indices indicated. Notice the FORTRAN style array access.
Index based loops are convenient when complex ranges or differencing patterns are needed. For commonly occurring patterns use range based loops instead.
Looping over Cells¶
Range based loops over cells are used when the order of iterations does not require any special control. A typical construction is:
#pragma omp parallel
{
for (auto cell : InteriorCellRange(some_field,n))
some_field(cell,0) *= another_field(cell,1);
}
In this example the first component of some_field is multiplied by the second component of another_field. Putting the loop inside a parallel region causes the InteriorCellRange object to automatically partition the iterations among the threads. The InteriorCellRange is so named because it does not include ghost cells. To include them use EntireCellRange.
Caution
If for some reason you nest auto-threaded loops inside a parallel section, you may get unexpected results.
If an iteration index is required, one may use the more explicit notation:
#pragma omp parallel
{
CellRange range(some_field,n,false);
for (auto it=range.begin();it!=range.end();++it)
{
tw::cell cell = *it;
some_field(cell,1) = it.global_count();
}
}
Here, the iterator method global_count is used to get the global index of the iteration, which is unique across threads. The explicit example brings out the three elements of iterating through a Field: the range (specific type CellRange), the iterator (automatically typed variable it), and the reference (specific type tw::cell). The CellRange range is the generalization of InteriorCellRange and EntireCellRange. The boolean argument chooses whether to include ghost cells.
Note
More elaborate ghost cell inclusion patterns are intended for future development.
Looping over Strips¶
A frequent pattern is operating on strips of cells. Often one would like to repeat the same strip-wise operations along each axis. Strip ranges make this simple.
int fixed_ax = 0; // often we want to fix the position on the time axis
int fixed_pos = 1; // often there is only 1 time index
for (int ax=1;ax<=3;ax++)
{
#pragma omp parallel
{
for (auto strip : StripRange(some_field,ax,fixed_ax,fixed_pos,strongbool::no))
for (int s=1;s<=Dim(ax);s++)
some_field(strip,s,0) *= another_field(strip,s,1);
}
}
The StripRange takes a new argument, an integer giving the axis parallel to the strips. To avoid errors in the order of arguments, we require the strongly typed strongbool to indicate ghost cell inclusion.
Handling Multiple Topologies¶
The same iterator can be passed into any number of field objects provided the topologies differ only in the number of internal dimensions. If the topologies differ in any other way you need an iterator for each such topology.
The case that is most likely to occur is operating on fields with different time dimensions. The standard library’s zip function can be very helpful in such cases:
for (int ax=1;ax<=2;ax++)
{
#pragma omp parallel
{
for (auto [fs,gs] : std::views::zip(
StripRange(f,ax,0,1,strongbool::no), // strips at time level 1, perhaps this field only has 1 time level
StripRange(g,ax,0,2,strongbool::no)) // strips at time level 2, perhaps this field has many time levels
{
for (int s=1;s<=Dim(ax);s++)
f(fs,s,0) *= g(gs,s,0);
}
}
}
Vectorization¶
In order to promote compiler vectorization, one has to commit to a particular storage pattern. Special templated ranges and references must be used. The template argument is an integer identifying the packed axis. Once this type of construction is used, the storage pattern cannot be changed, unless all the code that makes use of vectorizing iterators is modified.
Suppose we have a Field with axis 3 as the packed axis. Then an optimized loop might be constructed as follows:
#pragma omp parallel
{
for (auto v : VectorStripRange<3>(some_field,0,1,false))
{
#pragma omp simd
for (tw::Int i=1;i<=Dim(3);i++)
some_field(v,i,0) *= another_field(v,i,1);
}
}
Here, we have again assumed the block is defined inside a derivative of StaticSpace. It is important to understand that this construction uses thread parallelism across strips, and vector parallelism along strips. Therefore it is not effective for 1D problems.
Differencing¶
The Field class provides for differencing patterns that occur often in computational physics. For example:
#pragma omp parallel
{
for (auto v : VectorStripRange<3>(some_field,0,1,false))
{
#pragma omp simd
for (int i=1;i<=Dim(3);i++)
A(v,i,0) = B.d2(v,i,0,2);
}
}
In mathematical notation this would be:
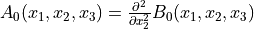
Note
When applying differencing operators the range must not include ghost cells.
Message Passing¶
The most common message passing pattern is to update the ghost cells in a domain using information from neighboring domains. This can be accomplished in one function call. An example of a complete parallel calculation follows.
// Assume we are in a module
Field A;
A.Initialize(2,*this,owner); // two components, other axes are inherited from `*this`
DoSomethingToLoadFieldWithData(A);
// Carry out work on interior cells using a thread team.
// This will create a team of threads for each MPI process.
#pragma omp parallel
{
for (auto cell : InteriorCellRange(A,1))
A(cell,0) += A.d1(cell,1,1); // centered derivative of component 1 in 1-direction
}
// All that remains is to load the ghost cells using the neighbor's data
A.CopyFromNeighbors(Rng(0)); // only need to copy component 0
Message passing is a costly operation. The above code could be optimized by noting that the differencing operation is only along one axis, and therefore the ghost cells bounding that axis are the only ones that have to be updated. To take advantage of this the last line could be replaced with
A.DownwardCopy(xAxis,Rng(0),1); // update 1 ghost cell layer moving data in the negative x-direction only
A.UpwardCopy(xAxis,Rng(0),1); // update 1 ghost cell layer moving data in the positive x-direction only
This operation is roughly 3 times faster (internally, CopyFromNeighbors calls the same two functions, but once for each axis).